DO TECH
Le coeur de métier de Data Observer est le traitement de « la donnée textuelle » : collecte, structuration, enrichissement, qualification, analyse et visualisation (« text mining »).
Collecte de données
Nous cherchons et structurons les données utiles via nos crawlers et robots de collecte.
Data Observer dispose de ses propres solutions et infrastructure pour ses moteurs de recherche. Nos experts en technologies open source Apache Lucene / Solr et Elasticsearch développent des moteurs de recherche sur mesure, s’adaptant à chaque besoin spécifique de fouille de données.
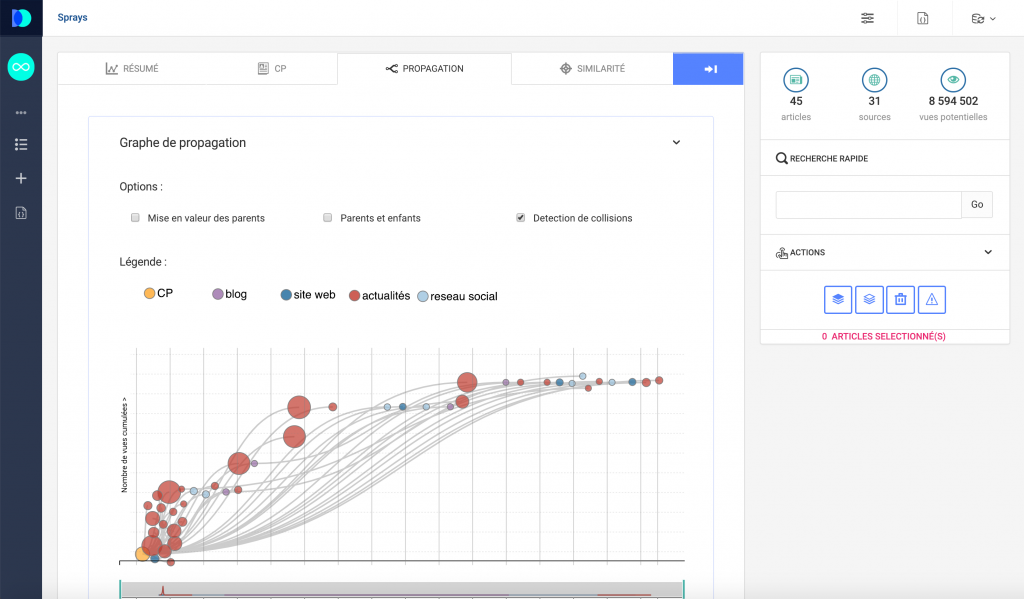
Exploration de données
Nous enrichissons les données collectées grâce à nos algorithmes d’extraction de connaissance.
Nous réalisons des traitements de données sur-mesure (« data on demand ») faisant appel à des algorithmes issus de notre R&D dans les domaines du machine learning (apprentissage automatique), du big data (traitement des données massives) et du traitement automatique des langages (TAL).
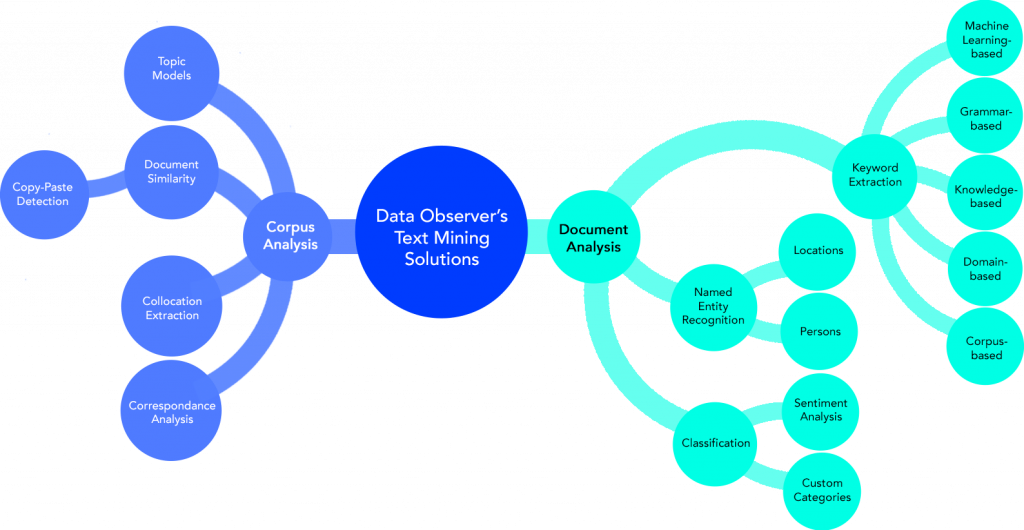
Modélisation de données
Nous agrégeons et représentons les données enrichies avec les formats et les supports les plus adaptés pour exploiter les données enrichies.
Nos experts en visualisation (« data visualization ») vous accompagnent pour représenter des ensembles de données complexes afin de les rendre facilement compréhensibles et actionnables.